So for a while I had a scraper running, which, once a day, scraped housing prices from chosen regions in Germany.
I accumulated about 6 month of data until I stopped it, mainly because I didn’t feel like I’d ever properly utilise it.
I decided to at least show some of it.
This post is basically excerpts from a Jupyter notebook.
A link to the data can be found at the end.
Small side-note: The diagrams in this post are best viewed in day mode. Sorry, fellow night-moders🌑
The data was split into one newline delimited JSON per day.
So first, read it into a DataFrame.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
importosimportjsonfromtypingimportList,Dictdefread_data(path:str)->List[Dict]:""" Reads all JSONs from the data folder. """data=[]forfilenameinos.listdir(path):iffilename.endswith(".json")orfilename.endswith(".jl"):withopen(os.path.join(path,filename))asf:forjlinf:data.append(json.loads(jl))returndataimportpandasaspdraw_data=pd.DataFrame(read_data("."))
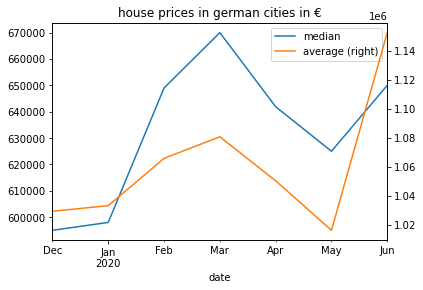
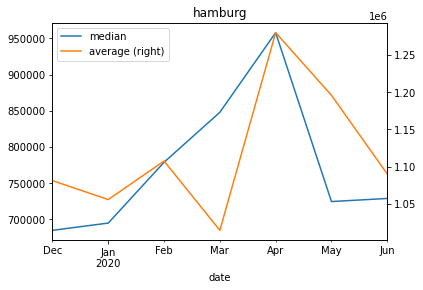
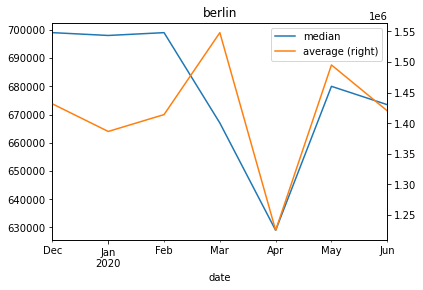
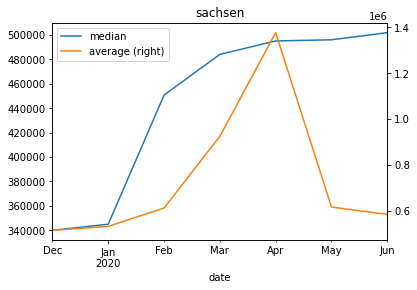
Let’s get an overview of the totals. Let’s plot the overall average and median.
1
2
3
4
5
6
7
agg_per_month=d[["date","search_region","price_num"]].copy()agg_per_month=agg_per_month[["date","price_num"]][agg_per_month["price_num"].notna()]avg_per_month=agg_per_month.rename(columns={"price_num":"average"}).resample('M',on="date",kind="timestamp").mean()med_per_month=agg_per_month.rename(columns={"price_num":"median"}).resample('M',on="date",kind="timestamp").median()ax=med_per_month.plot()avg_per_month.plot(ax=ax,secondary_y=True,title="house prices in german cities in €")
Average and median overall
One can definitly see the dent that the corona crisis created.
Let’s dive a bit into the various cities and regions.
Since I’m a data engineer, and much more about collection and providing data, than about analysing, I will do exactly what I do best and provide the data.
I packed it all into one JSON, instead of many, and compressed it with 7z.
What did I learn?
First of all, I’m not much of a data scientist.
While I do have ideas of what else I could with the data, it does not really motivate me to keep on going.
For example, one could split out prices by area, rooms, city center or suburbs, …
Working with pandas also does not feel entirely intuiative to me, mostly because most of data wrangling I usually do between low-level languages and python.
And whenever I really do want to display some results, I fall back to tables and excel.
Which admittedly works fine for pretty much all my use-cases.
And although it’s nice to try out new things, sticking to what you love to do usually yields in more fun.
Especially for side projects!😃
So, look forward to that. Still, this might not be my last dip into dataframes, notebooks and plotting.
A Wonka Story This is no longer in the current news cycle, but definitely needs to be filed under "stuff too insane for Charlie to make up", or maybe "promising screwball comedy plot line to explore", or even "perils of...
Today's links The antitrust case against Apple: End of the line for Apple exceptionalism. Hey look at this: Delights to delectate. This day in history: 2009, 2014, 2023 Upcoming appearances: Where to find me. Recent appearances: Podcasts, events and m…
2024/03/19A Commentary on Defining ObservabilityRecently, Hazel Weakly has published a great article titled Redefining Observability. In it, she covers competing classical definitions observability, weaknesses they have, and offers a practical reframing o…